Causal Machine Learning: la nuova frontiera del decision-making aziendale
Scoprire il nesso causa-effetto: le strategie per migliorare il processo decisionale e fare previsioni più accurate
Pubblicato su Mit Sloan Management Review Italia, Maggio/Giugno/Luglio 2025.
L’apprendimento automatico è oggi ampiamente utilizzato per guidare le decisioni nei processi in cui è sufficiente misurare la probabilità di un risultato specifico, per esempio, se un cliente rimborserà un prestito. Tuttavia, poiché la tecnologia, nella sua applicazione tradizionale, si basa su correlazioni per fare previsioni, le intuizioni che offre ai manager, nel migliore dei casi sono imperfette, quando si tratta di anticipare l’impatto di scelte diverse sui risultati aziendali (Feuerriegel et al., 2022a).
Consideriamo i dirigenti di una grande azienda che devono decidere quanto investire in Ricerca & Sviluppo (R&S) nel prossimo anno. Utilizzando il metodo di analisi Machine Learning (ML) tradizionale, possono chiedersi cosa accadrà quando aumenteranno la spesa. Potrebbero trovare una forte correlazione tra livelli di investimento più elevati e ricavi più alti quando l’economia è in crescita. E potrebbero concludere che, dal momento che le condizioni economiche sono favorevoli, dovrebbero aumentare il budget per la R&S.
Ma dovrebbero davvero? E se sì, di quanto? Anche i fattori esterni, come i livelli di spesa dei consumatori, le ricadute tecnologiche dei concorrenti e i tassi di interesse influenzano la crescita dei ricavi. Confrontare il modo in cui diversi livelli di investimento potrebbero influire sui ricavi, tenendo conto di queste altre variabili, è utile per il manager che cerca di determinare il budget per la R&S che porterà i maggiori benefici all’azienda.
Il Causal ML, un’area emergente dell’apprendimento automatico, può aiutare a rispondere a queste domande what if attraverso l’inferenza causale. Analogamente a come i marketer utilizzano i test A/B per dedurre quale tra due annunci pubblicitari è in grado di generare più vendite, il Causal ML può informare su cosa potrebbe accadere se i manager dovessero intraprendere una particolare azione (Feuerriegel et al., 2022b).
Questo rende la tecnologia utile in molte delle stesse funzioni aziendali che utilizzano il ML tradizionale, tra cui lo sviluppo del prodotto, la produzione, la finanza, le Risorse Umane e il marketing (von Zahn et al., 2024). Il ML tradizionale è ancora l’approccio ideale quando l’unico obiettivo è quello di fare previsioni, come per esempio se i prezzi delle azioni aumenteranno o quali prodotti i clienti acquisteranno con maggiore probabilità. Quando un’azienda vuole prevedere cosa accadrebbe se prendesse una decisione rispetto a un’altra, per esempio se è più probabile che uno sconto del 10% o nessuno induca un cliente a ripetere l’acquisto, ha bisogno di un ML causale.
La nostra ricerca sull’apprendimento automatico e sull’AI e la nostra esperienza nell’aiutare le aziende ad applicare il ML causale indicano un percorso per utilizzare con successo questa tecnologia (Box La ricerca). Le aziende avranno bisogno anche delle giuste competenze e dovranno aumentare l’alfabetizzazione dei dipendenti in materia di ML causale.
Cosa può e non può fare il ML causale
Il ML causale è uno strumento potente, ma i manager potrebbero trovare il nome fuorviante. L’etichetta ‘previsione controfattuale’ rifletterebbe più accuratamente ciò che fa: prevedere i risultati sulla base di azioni ipotetiche. La tecnologia è meglio compresa come un modo per fare ipotesi migliori piuttosto che come una fonte di risposte definitive. Inquadrandola in questo modo, si può ricordare ai manager di non sovrainterpretare i risultati.
Lo fa utilizzando l’inferenza causale, che esamina i risultati passati per comprendere le relazioni di causa-effetto tra le variabili. Invece di concentrarsi sul motivo per cui qualcosa è accaduto, il Causal ML applica queste relazioni per prevedere gli effetti degli interventi in contesti nuovi e orientati al futuro.
Tuttavia, il metodo non è in grado di spiegare perché esista una relazione causale tra un particolare fattore e il risultato su cui influisce. Per esempio, un modello di Causal ML potrebbe prevedere che la riduzione di un budget per la R&S faccia diminuire le entrate, ma non spiegherebbe perché esiste questa relazione o se i fattori confondenti – che influenzano sia la decisione sia il risultato – potrebbero cambiare e invalidare la previsione. I manager dovrebbero utilizzare la loro esperienza nel settore per valutare se una determinata previsione ha senso. Questo approccio aiuta a garantire che le previsioni del modello siano interpretate correttamente e rimangano rilevanti per le decisioni del mondo reale. Come il Machine Learning tradizionale, il Causal ML è più efficace quando i manager dispongono di grandi volumi di dati, le opzioni sono chiaramente definite e il risultato desiderato è ben compreso. In genere non è adatto a decisioni una tantum e a scenari che richiedono intuizione o creatività.
Scegliere il problema e i dati giusti
Il Causal ML è più adatto a prevedere gli esiti di decisioni semplici che sono supportate da ampi dati storici provenienti da fonti interne ed esterne. Le domande sulle operazioni possono essere buone candidate per l’approccio, perché sono prese frequentemente e le aziende hanno molti dati a supporto (von Krogh, Ben-Menahem e Shrestha, 2021). Di seguito sono riportati alcuni esempi di utilizzo del Causal ML in questo contesto:
- Booking.com raccoglie i dati di migliaia di prenotazioni alberghiere ogni ora. I marketer dell’azienda utilizzano il metodo di analisi causale per determinare non solo se concedere sconti, ma anche quali clienti dovrebbero ottenerli.
- Il produttore di cioccolato Lindt dispone di numerosi dati sulle condizioni ambientali, sulle attrezzature, sul confezionamento e su altri fattori che influenzano la qualità dei suoi tartufi, famosi in tutto il mondo. I responsabili della produzione utilizzano il Causal ML per aiutarli a mettere a punto parametri come la temperatura delle macchine e le configurazioni degli stampi per tartufi (ETH AI Center, 2023).
- Hitachi ABB Power Grids si è affidata al metodo di Causal ML per ridurre i tassi di guasto nel suo processo di produzione di semiconduttori, utilizzando i dati sulle prestazioni delle macchine. È riuscita a dimezzare la perdita di rendimento identificando la combinazione di macchine che produceva costantemente i chip di qualità migliore (Senoner, Netland e Feuerriegel, 2022).
Presso Novartis, i manager istruiti sulle capacità dei diversi tipi di ML sono stati in grado di identificare diverse attività decisionali in cui la sostituzione di quello tradizionale con il Causal ML offriva vantaggi significativi. Avevano chiesto a un modello di ML tradizionale se l’aumento del budget di marketing avrebbe aumentato le vendite, ma le sue previsioni non li aiutavano a decidere come allocare tale budget. Hanno deciso di utilizzare il Causal ML per valutare come diverse campagne promozionali avrebbero potuto influire sulle vendite future. Hanno utilizzato le previsioni per distribuire le risorse alle campagne che probabilmente sarebbero state più efficaci.
Una decisione adatta al Causal ML può essere espressa come un numero o una scelta binaria (per esempio, un importo di ricavi o un acquisto/possesso). Può anche essere formulata come una domanda su quale azione intraprendere: stanziare un budget di marketing di 10mila o 15mila dollari per il prossimo trimestre, oppure offrire uno sconto del 10% o nessuno su un prodotto (Wasserbacher e Spindler, 2022).
Inoltre, il metodo Causal ML non può affrontare efficacemente tutti i potenziali casi d’uso, anche se in apparenza sembra adatto a questo scopo. I confondenti – le variabili che influenzano sia l’esito sia la decisione – introducono distorsioni che influenzano le previsioni e devono essere tenuti in considerazione. Possono essere difficili o impossibili da testare e influenzano l’accuratezza delle previsioni. Se, per esempio, i dati sono disponibili solo per le vendite di prodotti durante una fase di crescita economica, le previsioni sulle vendite di prodotti durante una fase di contrazione saranno meno affidabili.
Quando i manager hanno determinato ciò che vogliono decidere, identificato il modo in cui misureranno il risultato e affermato di avere dati sufficienti, possono iniziare a lavorare con i data scientist per assemblare e categorizzare i dati per costruire il loro modello di Causal ML. I leader aziendali e altre persone con conoscenze di dominio sono partner essenziali dei data scientist e degli esperti di ML nella costruzione di modelli di ML causale che forniscano risultati affidabili.
Per addestrare il modello a cogliere relazioni complesse di causa-effetto sono necessari i dati di almeno alcune decine, e idealmente centinaia o migliaia, di decisioni storiche. Con una quantità massiccia di dati, il modello può scoprire connessioni tra variabili che potrebbero essere sconosciute ai manager o difficili da quantificare. Meno dati portano a previsioni meno accurate.
In linea di massima, il metodo di analisi causale richiede tre categorie di dati a cui si è accennato in precedenza: decisioni, esiti e fattori confondenti. I dati sulle decisioni comprendono ciò che i manager hanno fatto in passato, come i livelli di personale o i budget stabiliti, gli sconti offerti, gli investimenti effettuati o i processi modificati. I dati sui risultati possono includere qualsiasi risultato aziendale misurabile, come il volume delle vendite, la crescita dei ricavi, le metriche di qualità o la produttività.
I fattori confondenti possono provenire da fonti interne o esterne. Possono includere le condizioni economiche, la composizione della forza lavoro e il comportamento dei concorrenti, e possono variare a seconda della decisione da prendere. Per una decisione di marketing, il tipo di dispositivo utilizzato dai clienti può essere un fattore di confondimento, perché chi possiede uno smartphone più costoso può tendere a spendere di più, indipendentemente dal fatto che risponda o meno a un incentivo.
Per esempio, la Neue Zürcher Zeitung, un’azienda mediatica internazionale che pubblica il quotidiano a maggiore tiratura della Svizzera, ha implementato il Causal ML per migliorare l’efficacia delle decisioni di promozione dei contenuti da parte dei redattori. La variabile decisionale era la promozione di un articolo online su una delle due prime pagine che erano servite ai lettori. La variabile di risultato era un punteggio di performance che combinava il traffico del sito web, il coinvolgimento dei lettori e le sottoscrizioni di abbonamenti. I fattori di confondimento includevano fattori temporali (come l’ora del giorno), caratteristiche del contenuto (come il formato dell’articolo), indicatori di performance passati (inclusi i clic) e decisioni di promozione passate (incluso se l’articolo era stato promosso altrove).
Identificare i possibili fattori causali
Una lezione preziosa del nostro lavoro è stata l’utilità di abbozzare un grafico causale su una lavagna che illustri le relazioni previste tra l’esito, la decisione e i fattori confondenti all’inizio del processo di sviluppo del modello. La conoscenza e l’esperienza dei manager sono essenziali in questo caso, perché hanno preso ripetutamente decisioni e imparato ad anticipare certi risultati.
Il grafico causale indica agli scienziati dei dati (che dovrebbero essere esperti di inferenza causale) se trattare una variabile come causa o come effetto nel modello. In questo modo, il team può escludere errori di causalità inversa. In altre parole, può assicurarsi che il modello non interpreti erroneamente una variabile come causa di un’altra quando, in realtà, l’effetto è opposto.
Immaginate una celebrità con milioni di follower sui social media. Se non sappiamo molto sui social media o sulla celebrità, potremmo concludere che la fama deriva dall’avere un alto numero di follower. È più probabile che sia vero il contrario. Come ha osservato anche un adolescente medio, per far sì che milioni di sconosciuti seguano i loro account sui social media, devono prima fare qualcosa che li faccia notare. Nel caso della nostra domanda sulla spesa in R&S, il budget influenza le entrate, non il contrario. Nel frattempo, fattori confondenti come il clima economico, le tendenze del mercato o la competenza del team sono riconosciuti come fattori che guidano sia la decisione di budget sia i risultati aziendali, ma non sono influenzati da nessuno dei due. Il modello terrebbe conto di tutto questo (Figura 1).
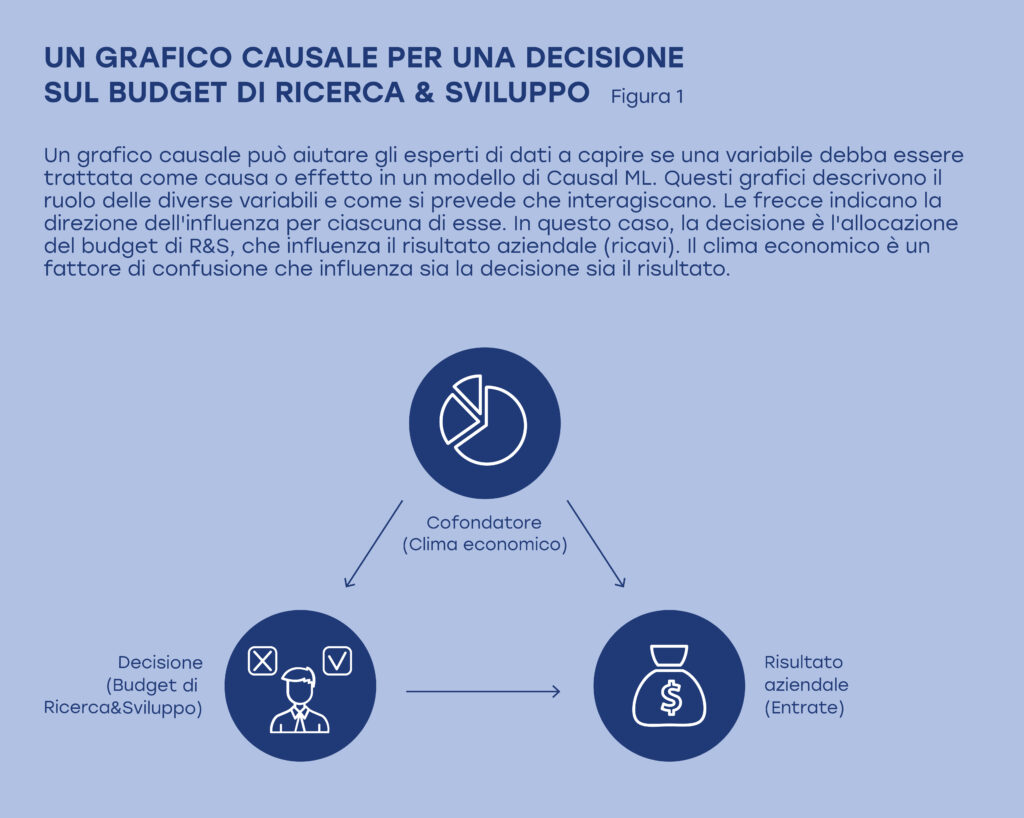
Scegliere l’uscita
Successivamente, i manager devono scegliere il tipo di risposta che il modello deve fornire in risposta alla domanda (in statistica, l’output o stima): può prevedere il risultato finale di una decisione o il beneficio relativo di un’alternativa rispetto a un’altra.
Ognuno di questi risultati può essere utile, a seconda del modo in cui il manager sta pensando a una decisione. Concentrarsi sui risultati finali, come i ricavi potenziali in diversi scenari di budget o gli incentivi personalizzati per i singoli clienti, aiuta nella pianificazione strategica. Tuttavia, confrontare gli effetti incrementali di diverse decisioni è spesso sufficiente per prenderne una: se un manager vuole sapere quale di due annunci pubblicitari è in grado di incrementare le vendite in modo più efficace, non ha necessariamente bisogno di prevedere l’entità dei ricavi che ciascuna variante potrebbe generare. Ha solo bisogno di sapere il beneficio relativo: che un annuncio è in grado di generare tre volte più entrate dell’altro. Inoltre, concentrarsi sui benefici relativi genera previsioni più affidabili che concentrarsi sui risultati finali. Raccomandiamo di perseguire solo la granularità necessaria.
I redattori della Neue Zürcher Zeitung erano interessati a prevedere le percentuali di clic effettive per ogni articolo promosso, ma l’azienda ha scelto invece di prevedere il probabile guadagno netto di prestazioni derivante dalla promozione di un articolo. Questo approccio ha permesso al Causal ML di fare previsioni più accurate su quali contenuti, se promossi, avrebbero aumentato i clic e gli abbonamenti. I redattori hanno imparato che la promozione di articoli scritti dal caporedattore aumentava significativamente entrambi i risultati (Persson, Feuerriegel e Kadar, 2023). I redattori avevano promosso con parsimonia gli articoli del caporedattore e i risultati sono serviti come punto di partenza per rivedere la loro strategia promozionale.
Addestramento, test e validazione del modello
Una volta che i manager hanno definito la decisione che vogliono prendere e il tipo di output che preferiscono, gli scienziati dei dati e dell’apprendimento automatico possono scegliere il modello di Causal ML più adatto al lavoro. Una volta implementato il modello, gli ingegneri dell’apprendimento automatico lo addestreranno utilizzando i dati precedentemente categorizzati.
La fase finale consiste nel testare e convalidare il modello di Causal ML nella pratica, per garantire che sia affidabile e che le sue previsioni si traducano in migliori prestazioni aziendali. La convalida offre anche l’opportunità ai responsabili delle decisioni, compresi i dirigenti, di ottenere fiducia nelle sue previsioni. Iniziare con problemi relativamente semplici e lineari, in cui è possibile identificare e valutare alternative decisionali chiare, rende questa fase più facile da realizzare.
I test e la convalida richiedono attenzione perché i manager possono osservare solo il risultato della decisione presa nel mondo reale. Non hanno modo di sapere quale sarebbe stato il risultato se fosse stata presa una decisione diversa. Due strategie, human in the loop e il noto approccio dei test A/B, si sono dimostrate vincenti.
Neue Zürcher Zeitung ha scelto di integrare le raccomandazioni del modello con i processi decisionali umani (Ibidem). Il modello di Causal ML raccomanda quali contenuti promuovere, ma sono i redattori a prendere le decisioni finali. Il modello si basa sulle stesse informazioni che i redattori usavano in precedenza per prendere le loro decisioni di promozione; quindi, possono fidarsi che il modello non manchi di elementi chiave. Le raccomandazioni del modello di Causal ML corrispondono in genere alle sensazioni dei redattori, il che dà loro la certezza dell’affidabilità del modello.
Alcune decisioni sono difficili e i redattori sanno che il loro giudizio non è perfetto. Nei casi in cui Causal ML raccomanda una decisione diversa da quella che avrebbero preso loro, i redattori possono testare la raccomandazione e vedere il risultato. Con il tempo, dovrebbero vedere che il metodo Causal ML è in grado di fornire raccomandazioni affidabili in situazioni ambigue. A quel punto, potranno seguire più spesso le raccomandazioni di Causal ML invece del loro istinto.
Hitachi ABB ha utilizzato i test A/B per convalidare i modelli di Causal ML costruiti per migliorare la qualità della produzione. In un’applicazione, i manager hanno utilizzato il modello per prevedere quale macchina, tra le varie, avrebbe prodotto la migliore qualità nelle fasi di incisione e impiantazione del processo di fabbricazione dei semiconduttori, contribuendo alla produzione di qualità più elevata in generale.Per confermare l’affidabilità delle previsioni, i manager hanno condotto un esperimento controllato in cui hanno cambiato la macchina utilizzata per l’incisione e l’impianto, mantenendo invariate le macchine utilizzate per gli altri processi. Hanno scoperto che la macchina migliore per l’incisione e l’impianto era la stessa che il modello di ML causale aveva previsto. Grazie al Causal ML, i manager sono stati in grado di trovare e risolvere la fonte dei problemi di produzione in modo più efficiente di quanto avrebbero potuto fare con i metodi manuali o con il ML tradizionale (Senoner et al., 2021).
Preparare l’organizzazione
Sebbene il Causal ML abbia il potenziale per migliorare le decisioni, l’implementazione di questi sistemi richiede un alto livello di alfabetizzazione all’AI nella forza lavoro, competenze tecniche specializzate e pazienza, perché lo sviluppo di questi progetti può richiedere più tempo rispetto alle applicazioni di ML tradizionali. I manager possono preparare le loro organizzazioni istruendo se stessi e la loro forza lavoro sull’AI causale e costruendo i team interdisciplinari necessari per sviluppare le applicazioni.
Molte aziende oggi investono molto nella formazione dei dipendenti sui modelli tradizionali di ML e di AI Generativa (come ChatGpt) per rimanere competitive e innovative. Se l’organizzazione intende utilizzare il Causal ML, deve includere questa tecnologia nei suoi sforzi di alfabetizzazione all’AI. I dipendenti attenti ai punti di forza e ai limiti dei diversi approcci all’AI saranno in grado di trovare le opportunità per utilizzarli in modo efficace.
Abbiamo scoperto che per eccellere nell’utilizzo del Causal ML, i team hanno bisogno di una forte esperienza nella scienza dei dati e nell’apprendimento automatico, oltre che di conoscenze di settore. Tuttavia, la creazione di questi team può essere costosa, soprattutto quando le aziende devono assumere data scientist o rivolgersi a consulenti e partner esterni.
Inoltre, i data scientist e gli ingegneri dell’apprendimento automatico sono tipicamente assegnati a team diversi. Devono lavorare a stretto contatto durante lo sviluppo e l’implementazione di modelli di Causal ML e avere un forte impegno con gli stakeholder aziendali che hanno conoscenze di dominio. (La conoscenza del dominio è essenziale anche nell’apprendimento automatico tradizionale, ma spesso è applicata in modo meno rigoroso perché i team non considerano a fondo le relazioni sottostanti tra le variabili quando costruiscono i modelli).
Per esempio, alla Neue Zürcher Zeitung, le conoscenze dei redattori e degli addetti al marketing sui processi editoriali, sulle preferenze dei clienti e sugli obiettivi a lungo termine del marchio aiutano i data scientist a definire le variabili che misurano questi fattori. In Hitachi ABB, gli ingegneri forniscono le informazioni necessarie per definire le variabili di produzione da includere nei modelli.
I team interdisciplinari sono spesso afflitti dalla mancanza di comprensione, vocabolario e modalità di lavoro comuni. I manager devono promuovere un ambiente in cui la collaborazione interfunzionale possa prosperare e in cui tutte le parti interessate siano coinvolte nel processo di sviluppo del modello. Workshop, riunioni e sessioni di formazione regolari in cui data scientist, ingegneri dell’apprendimento automatico ed esperti di dominio esplorano insieme i problemi, perfezionano i modelli e discutono insieme le implicazioni dei risultati possono favorire un ambiente in cui la collaborazione interfunzionale prospera.
L’apprendimento automatico ha cambiato il modo in cui numerose organizzazioni prendono le decisioni; il Causal ML può approfondire ulteriormente le conoscenze prevedendo gli effetti delle diverse scelte sui risultati aziendali. Le aziende hanno maggiori probabilità di trarre vantaggio dall’apprendimento automatico quando i responsabili delle decisioni si fidano dei risultati. Sapere cosa può fare il Causal ML e come si confronta con il ML tradizionale può aiutare a scegliere i progetti giusti per ogni tecnologia e ad aumentare i tassi di successo.
Quando i manager utilizzano la Causal ML in modo prudente per esplorare le opzioni per le decisioni più semplici, possono migliorare significativamente le loro operazioni e, in ultima analisi, i loro risultati finanziari.

Bibliografia
S. Feuerriegel, Y.R. Shrestha, G. von Krogh, et al., “Bringing Artificial Intelligence to Business Management”, Nature Machine Intelligence 4, no. 7 (luglio 2022): 611-613; e P. Hünermund, J. Kaminski, and C. Schmitt, “Causal Machine Learning and Business Decision-Making“, SSRN, aggiornato al 19 febbraio 2022, https://ssrn.com.
S. Feuerriegel, D. Frauen, V. Melnychuk, et al., “Causal Machine Learning for Predicting Treatment Outcomes”, Nature Medicine 30 (aprile 2024): 958-968; V. Chernozhukov, C. Hansen, N. Kallus, et al, “Applied Causal Inference Powered by ML and AI”, file PDF (pubblicato dagli autori il 28 luglio 2024), https:causalml-book.org; e C. Fernández-Loría e F. Provost, “Causal Decision-Making and Causal Effect Estimation Are Not the Same ... and Why It Matters”, Informs Journal on Data Science 1, no. 1 (aprile-giugno 2022): 4-16.
M. von Zahn, K. Bauer, C. Mihale-Wilson, et al., “Smart Green Nudging: Reducing Product Returns Through Digital Footprints and Causal Machine Learning”, Marketing Science, Articles in Advance, pubblicato online l’8 agosto 2024; E. Ascarza, “Retention Futility: Targeting High-Risk Customers Might Be Ineffective”, Journal of Marketing Research 55, no. 1 (febbraio 2018): 80-98; J. Yang, D. Eckles, P. Dhillon, et al., “Targeting for Long-Term Outcomes”, Management Science 70, no. 6 (giugno 2024): 3841-3855; e M. Kraus, S. Feuerriegel e M. Saar-Tsechansky, “Data-Driven Allocation of Preventive Care With Application to Diabetes Mellitus Type II”, Manufacturing & Service Operations Management 26, no. 1 (gennaio-febbraio 2024): 137-153.
G. von Krogh, S.M. Ben-Menahem e Y.R. Shrestha, “Artificial Intelligence in Strategizing: Prospects and Challenges”, in “Strategic Management: State of the Field and Its Future”, eds. I.M. Duhaime, M.A. Hitt e M.A. Lyles. (New York: Oxford University Press, 2021), 625-646.
“Perfezionata la produzione di cioccolato premium: AI’s Role in Quality Excellence”, ETH AI Center, 11 dicembre 2023, https://ai.ethz.ch.
J. Senoner, T. Netland e S. Feuerriegel, “Using Explainable Artificial Intelligence to Improve Process Quality: Evidence From Semiconductor Manufacturing”, Management Science 68, no. 8 (agosto 2022): 5704-5723.
H. Wasserbacher e M. Spindler, “Machine Learning for Financial Forecasting, Planning and Analysis: Recent Developments and Pitfalls”, Digital Finance 4 (marzo 2022): 63-88.
J. Persson, S. Feuerriegel e C. Kadar, “Off-Policy Learning for Audience-Wide Content Promotions“, documento di lavoro, 2023.
Senoner et al., “Using Explainable Artificial Intelligence”, 5704-5723.
